在Java Web的后台开发中,数据持久化操作是非常重要的一步,数据持久化,简单来说是将程序的数据保存在数据库中,将数据写入磁盘。JDBC是一种持久化机制,是我们最经常使用的,但是,有许多开源的框架有更好的操作性,例如Hibernate.
JDBC的优点和缺点
优点
直接底层操作,提供了很简单、便捷的访问数据库的方法,跨平台性比较强。灵活性比较强,可以写很复杂的SQL语句。
缺点
因为java是面向对象的,JDBC没有做到使数据能够面向对象的编程,使程序员的思考任然停留在SQL语句上。
操作比较繁琐,很多代码需要重写很多次。
如果遇到批量操作,频繁与数据库进行交互,容易造成效率的下降。
JDBC的程序操作可以封装一些什么内容?又不可以封装哪些内容?
Hibernate
为什么要使用Hibernate
- Hibernate实现了面向对象的数据库编程
- Hibernate比起JDBC来,在代码的书写上比较简单化了。
- Hibernate提出了缓存机制,这样可以使访问数据库的效率提高很大。
Hibernate的缺点
- 该框架程序员是没有办法干预SQL语句的生成
- 如果一个项目中,对SQL语句的优化的要求比较高,这个时候不能用Hibernate来做
- 表之间的关系很复杂的情况下,不能用Hibernate来做
- 如果一张表的数据超过了千万级别,也是不适合用hibernate来做
Hibernate的组成
持久化类
|
|
说明:持久化类中必须有一个默认的构造器,因为hibernate加载类是通过java的反射机制利用,默认的构造器创建持久化对象的。
映射文件
|
|
从映射文件中可以看出,该映射文件完成了从类到表、类中的属性到表中的字段的对应关系。
配置文件
|
|
- Hibernate.connection.url: 表示要链接的数据库地址
- Hibernate.connection.driver_class : 表示要链接的数据库的驱动类
- Hibernate.connection.username: 要连接的数据库的用户名
- Hibernate.connection.password: 要连接的数据库的密码
- Hibernate.dialect: 表示要使用的数据库的类型
- org.hibernate.dialect.MySQL5Dialect mysql数据库
- org.hibernate.dialect.Oracle9Dialect oracle数据库
- org.hibernate.dialect.SQLServerDialect SQLServer数据库
- hibernate.hbm2ddl.auto:
- validate:加载hibernate时验证创建表结构
- pdate:加载hibernate时自动更新数据库结构,如果表存在不用创建,如果不存在就创建。
- create:每一次加载hibernate时都创建表结构
- create-drop:加载hibernate时创建,退出时删除
使用Hibernate执行CRUD操作
增加
|
|
加载Hibernate的配置文件的有多重方法,一般使用Configuration.configure()方法加载配置文件的时候,配置文件是要在类的根目录中为什么呢?查看Hibernate的源码可以知道,使用该Configuration.configure()构造方法的时候是从根目录下加载该文件的,如下图: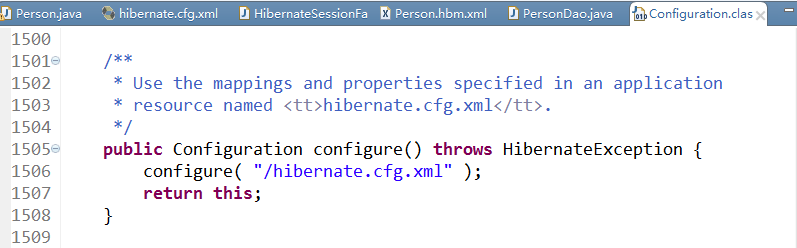
因为每次操作都是要进行配置文件的加载,和SessionFactory的创建,所以直接写一个Utils来方便使用:
使用上面的类,简化代码,进行更新,查找,删除的操作。
更新
|
|
查找
|
|
删除
|
|
Hibernate的流程
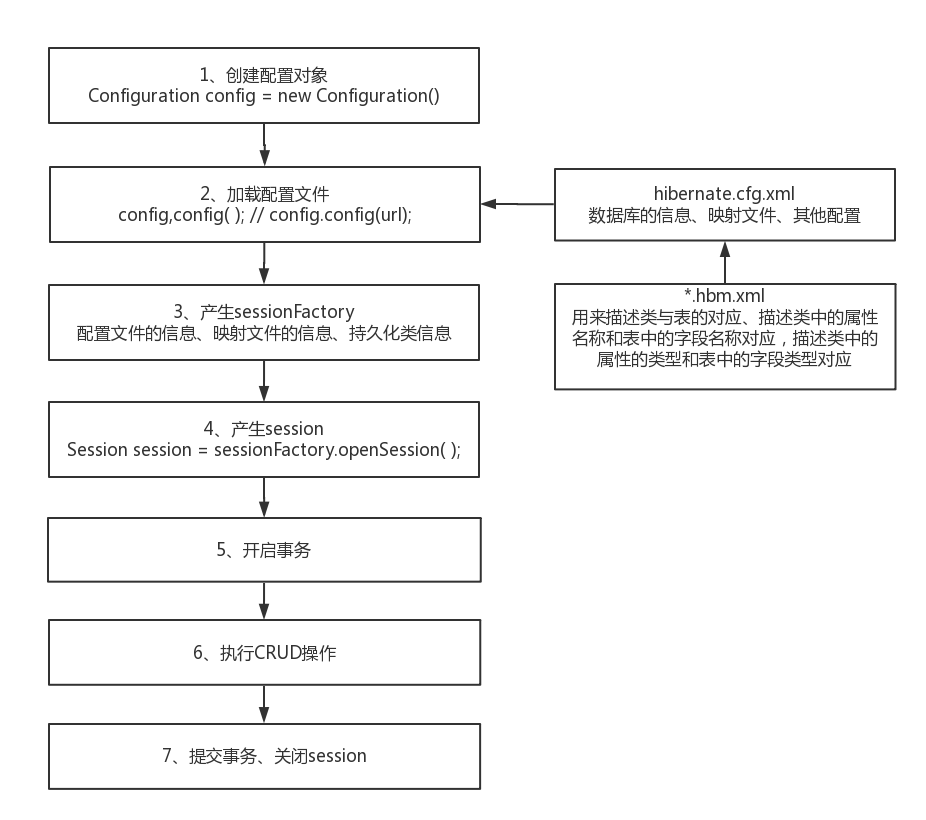
说明:
1、CRUD操作是由session来完成的。
2、在Hibernate中事务不是自动提交的。
简单例子的详细解析
Configuration类
利用该类加载了Hibernate的配置文件
sessionFactory类
- Hibernate配置文件的信息、持久化类的信息、映射文件的信息全部在该类中。
- sessionFactory对象有且只有一个
- sessionFactory的生命周期是整个Hibernate实例
- sessionFactory本身就是线程安全的
- 二级缓存在sessionFactory中存放。
- sessionFactory和数据库的连接没有直接的关系
session类
- CRUD操作由session来完成
- 一个session代表数据库的一个连接
session 内部执行流程
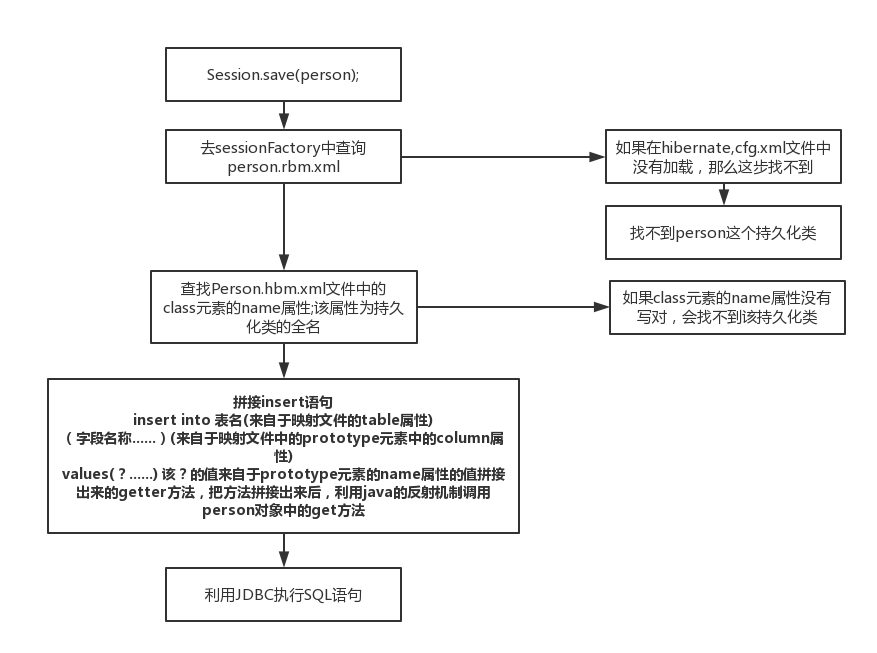
Hibernate中的类型
在Hibernate中有两种类型: java.type , hibernate type
Java type
Hibernate 内部之间提供了Java类型到数据库的对照表,如下图的官方文档中的基本数据类型截图:

说明: 用Java类型可以直接完成从Java类型到数据库类型的映射
Hibernate type
从上面可以看出,如果选择hibernate类型,需要查找该hibernate类型对象的Java类型,从而再找到数据库类型,所以Java类型效率是比较高。
主键的产生器
Increment
主键自动增长,但是不同于Identity,Increment是和数据中的主键自动增长是一样的,那么Hibernate是怎么实现的呢? 当我们向数据库中执行增加一条记录的时候,Hibernate是怎么执行?请看下面的图:

从Hibernate的查SQL语句的输出可以看出,在Increment设置下,执行SQL语句的时候是:先查找主键的最大值,再在最大值的基础上加1, 所以从这可以看出,使用Increment的效率比较低。
Assigned
需要由程序员手动赋值
那么我们在编程的时候是要对主键直接进行过设置,例如:
Identity
支持主键的自动增长
将这个进行配置之后,例如: 插入了3条记录,那么数据库中主键是 1, 2,3, 当删除主键为2的记录之后,再进行插入一条数据,就会主键值为4,数据库中记录主键值为:1,3,4 删除主键为3的记录,再插入一条记录,那么主键值为:1,4,5, 这样在数据库中并不是那么直观的看出所有的记录数。
UUID
|
|
持久化类中的属性必须是String类型
Native
Hibernate会根据数据库的不同,选择合适的主键的生成策略
Sequence
是oracle内部特有的内容,相当于uuid,所以是字符串类型。

