Java中存在几大非常有名的集合大佬,例如HashMap, HashTable,TreeMap等等,各大集合大佬们各有特色,那么他们的内部是怎么实现的呢?是不是非常好奇呢?当然本人也是非常好奇的,那么我们就慢慢的一步一步的了解他们吧,下面我们就先来了解HashMap这个集合。
HashMap的基本概述
首先,我们来看Java中对于HashMap的一个说明:
上面的这一段说明是说:Hash表是实现了 Map 接口的,实现了里面可选择的集合操作,其中允许了键和值为null的情况,HashMap除了不是线程安全和允许键和值可以为null的特殊性外,其他的和HashTable是非常现似的。当向集合中添加元素的时候,是不能保证集合中的元素是有序的,特别的是,它不能保证顺序是恒久不变的。
那么它的实现是怎么样的呢?接着往下看
HashMap的主要数据结构
|
|
从上面的源码我们知道HashMap 实现了Map
但是你们看
这个是不是比较有趣呢?HashMap不是再实现Map不是多余吗? 但是在Stack Overflow 上解释到:
在语法层面继承接口Map是多余的,这么做仅仅是为了让阅读代码的人明确知道HashMap是属于Map体系的,起到了文档的作用
那么元素是怎么在HashMap中储存的呢?
我们从源码中可以找到以下的数据结构:
Node节点和存储数组
从源码中可以知道,HashMap中有一个非常重要的字段(或者叫做 域),那个就是transient Node<K,V>[] table, 该字段是用于存储元素类型为Node的数组.
红黑树
JDK1.8版本对以前的HashMap进行了很大的修改,在JDK1.6中,HashMap采用桶+链表的实现,即:使用链表处理冲突,同时同一hash值的链表(Node)都存储在一个链表中,因此当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低,但是在JDK1.8中,HashMap采用桶+链表+红黑树实现,当链表长度超过阙值 8(为什么是8呢?后面会讲到HashMap中的重要属性)的时候,将转化为红黑树,而红黑树的查找和插入的效率都是非常高的,这样大大的减少了查找的时间。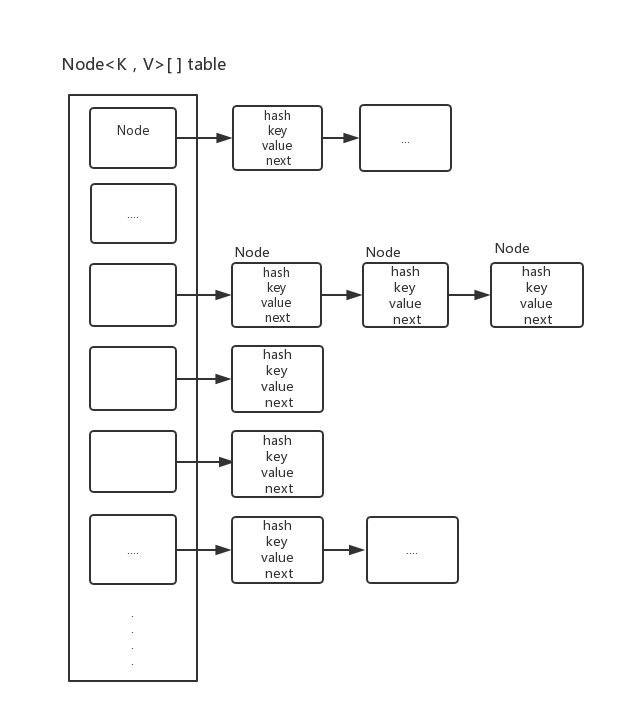
看了上面的图了之后,记住哦!当链表的长度大于8的时候,将会将链表转换为红黑树。
|
|
从上面的三个数据结构可以知道,Node元素实现了Map.EntryMap.Entry(K,V)就是定义了Entry的接口,定义了getKey(), getValue(), setValue(), equals()等一些抽象方法。HashMap的内部类Node实现这个接口。从源码中可以看到Node是里面存储的是链表。
有了以上桶+链表+红黑树,那么大致就是HashMap的实现了,首先HaspMap内部是有一个数组(也可以说是一个桶,桶排序算法也用的是这样的桶),里面的元素都是Node元素的链表。
构造函数
|
|
主要的属性
HashMap中的主要属性是一定要认识一下的,因为HasMap的一些特点很多是与属性有关的。
HashMap中的成员属性不得不说的得是填充比了, 它的默认值是0.75 ,如果实际元素所占容量占分配容量的75%时,就要扩容了,如果填充比很大,说明空间的利用率非常的大,但是此时的查找效率是会很低的,因为链表的长度很大,但是JDK1.8之后的使用了红黑树会效率会更高一些,HashMap本来是以空间换时间,所以填充比没有必要太大,但是填充比太小会导致空间的浪费,如果关注内存,那么填充比可以稍大,如果关注的是查找性能,填充比可以稍小。
元素的存放位置put/get方法
我们向HashMap中添加元素的时候是通过put(K,V)方法,取得元素的方法一般是get(),那么这两个方法是怎么实现的呢?
key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。理论上散列值是一个int型,如果直接拿散列值作为下标访问HashMap主数组的话,考虑到2进制32位带符号的int表值范围从-2147483648到2147483648。前后加起来大概40亿的映射空间。只要哈希函数映射得比较均匀松散,一般是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。你想,HashMap扩容之前的数组初始大小才16。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来访问数组下标。源码中模运算是在这个indexFor( )函数里完成的。
indexFor的代码也很简单,就是把散列值和数组长度做一个”与”操作.
顺便说一下,这也正好解释了为什么HashMap的数组长度要取2的整次幂。因为这样(数组长度-1)正好相当于一个“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值
但这时候问题就来了,这样就算我的散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。更要命的是如果散列本身做得不好,分布上成等差数列的漏洞,恰好使最后几个低位呈现规律性重复,就无比蛋疼。这时候“扰动函数”的价值就体现出来了,说到这里大家应该猜出来了。看下面这个图,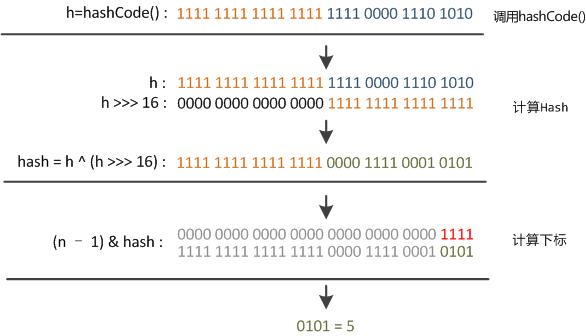
位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性.而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。
最后我们来看一下Peter Lawley的一篇专栏文章《An introduction to optimising a hashing strategy》里的一个实验:他随机选取了352个字符串,在他们散列值完全没有冲突的前提下,对它们做低位掩码,取数组下标。
结果显示,当HashMap数组长度为512的时候,也就是用掩码取低9位的时候,在没有扰动函数的情况下,发生103次碰撞,接近30%,而在使用了扰动函数之后只有92次碰撞。碰撞减少了将近10%,看来扰动函数确实是有功效的。
HashMap中查找元素方法的办法有多种,有get(Object key), containsKey(Object key), containsValue(Object value)这些查找键值对的方法:
HashMap的扩容机制
在HsahMap的四种构造函数中并没有对其中的成员变量Node< K,V > [] table 进行任何初始化的工作,从上面对hashMap中的主要的属性的分析知道,构造HashMap表的时候,如果不指定表的数组大小的情况下,默认大小是16,那么HashMap是如何构造一个默认的初始容量为16的空表的呢?如果Node数组中的元素达到 填充比*Node.length 的时候,HsahMap将会扩容。那么它是怎么扩容的呢?
我们直接上源码吧!
通过阅读和解释上面的源码可以知道:
该初始化的诱发条件是在向HashMap中添加第一个元素时,通过put< K key, V value >——>putVal(hash(key), key, value, false, true)——> resize()方法,一步一步的将元素添加到hashMap中。HashMap中尤其重要的resize()方法主要实现的了两个功能:
1、在table为数组为null的时候,对其进行初始化,默认容量是16;
2、当table数组为非空,但是需要调整HashMap容量的时候,将HsahMap容量翻倍。
该方法的解释是: 这个方法可以用来初始化HashMap的大小,或者重新调整HashMap的大小,变为原来的2倍。 在从旧的数组中拷贝元素到新的数组中的时候,是一个一个的遍历数组,元素的同时遍历链表(或者红黑树),所以这个过程是相当的耗时间的。
清空有删除
HashMap中提供了remove(Object key)方法来删除键值对,使用clear()清除所有的键值对的方法,这方法使用的时候需要比较小心。
其他方法:size(),isEmpty(),clone()
|
|
HashMap序列化
保存Node的table数组为transient的,也就是说在进行序列化时,并不会包含该成员,这是为什么呢?
为了解答这个问题,我们需要明确下面事实:
- Object.hashCode方法对于一个类的两个实例返回的是不同的哈希值
我们可以试着想下一下下面的场景
因为这个原因,HashMap重现了writeObject与readObject 方法
简单来说,在序列化时,针对Entry的key与value分别单独序列化,当反序列化时,再单独处理即可。
小结
HashMap的一些特点
线程非安全,并且允许key与value都为null值,HashTable与之相反,为线程安全,key与value都不允许null值。
不保证其内部元素的顺序,而且随着时间的推移,同一元素的位置也可能改变(resize的情况)
put、get操作的时间复杂度为O(1)。
遍历其集合视角的时间复杂度与其容量(capacity,槽的个数)和现有元素的大小(entry的个数)成正比,所以如果遍历的性能要求很高,不要把capactiy设置的过高或把平衡因子(load factor,当entry数大于capacity*loadFactor时,会进行resize,reside会导致key进行rehash)设置的过低。
负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。
由于HashMap是线程非安全的,这也就是意味着如果多个线程同时对一hashmap的集合试图做迭代时有结构的上改变(添加、删除entry,只改变entry的value的值不算结构改变),那么会报ConcurrentModificationException,专业术语叫fail-fast,尽早报错对于多线程程序来说是很有必要的。
Map m = Collections.synchronizedMap(new HashMap(…)); 通过这种方式可以得到一个线程安全的map。
扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
JDK1.8引入红黑树大程度优化了HashMap的性能。

