本篇文章是参考《Web全栈工程师的自我修养》章节所做的记录,同时,也增加了些许内容。

前端视角
前端工程师的职责之一是,让网站又快又好的展现在用户的浏览器中。
所以通过浏览中的开发者界面中可以发现很多HTTP请求的信息。这些信息包括以下内容:
- 发出的请求列表。
- 每个请求的开始时间,每个请求从开始的到结束所花费的时间。
- 请求类型(比如说是Img,JS,CSS,Media,Font,Doc等等)
- 请求的状态码(200:正常, 404:资源找不到,304:资源改变)
- 每个请求产生的流量消耗
- 每个请求gzip压缩前的体积,以及在本地gzip解压之后的体积
如下图: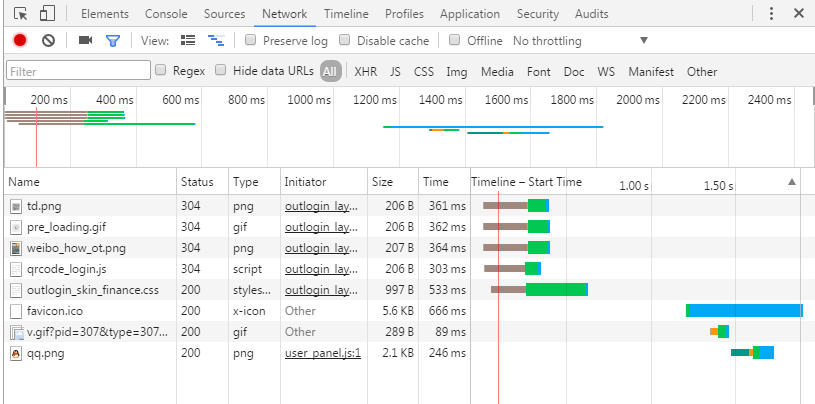
gzip是一种开源的数据压缩算法,其中的g是gratis代表免费的意思,HTTP/1.1协议允许客户端选择要求从服务器下载压缩内容,gzip是绝大多数客户端和服务器都支持的压缩算法,在压缩文本文件(比如HTML,CSS,JavaScript)时压缩效果很好。
通过查看站点的HTTP请求信息,可以获得很多的优化信息。下面就是一些基本的优化方法:
尽量减少同一域下的HTTP请求
现在的浏览器对同一个域名发起的并发连接数都做了一些限制,IE6/7 和Firefox2 的设计规则是,同时只能对一个域名发起两个并发连接。新版本的浏览器普遍把这一上限设置为4至8个。所以,如果浏览需要对某个域进行更多的连接,则要在用完当前连接之后,重复使用或者重新建立TCP连接。
由于浏览器针对资源的域名限制并发数,而不是针对浏览器地址栏中的页面域名,所以很多静态资源可以放在其他域名下(不同的子域名也被认为是不同的域名),如果只有一台服务器,可以把这些不同的域名同时指向一个IP,也就提高了对这台服务器的并发数连接数限制(不过要小心服务器压力过大)。
把静态资源放在非主域名下,这种做法除了可以增加浏览器并发,还有一个好处是,减少HTTP请求中携带的不必要的 cookie 数据。cookie 是某些网站为了辨别用户身份而存储在用户浏览器中的数据。 cookie 的作用域是整个域名,也就是说某个 cookie 存放在 google.com 域名下,那么所有资源的请求都会带上 cookie 数据。对于静态资源来说,这是毫无必要的,因为这对带宽和链接速度都造成了影响,所以我们一般把静态资源放在单独的域名下。
尽量减少每一个资源的体积
我们不仅要限制浏览器的请求数量,还要尽量减少每一个资源的体积,上面我们讲过http请求中有请求流量消耗这一项,所以如果你的资源体积越大,那么传输过程中消耗的流量就越多,等待的时间也越久。
图片格式的选择请参看文章Web性能优化:图片优化,这里就不做过多的说明。
对于比较大的文本资源。必须开启gzip压缩,因为gzip对于含有重复”单词”的文本文件,压缩率非常高,能有效提高传输过程。
后台视角
后台工程师对于HTTP的关注在于让服务器尽快响应,以及减少请求对服务器的开销。
浏览器限定对某个域的并发连接数,本身是对服务器的一种保护行为,这种善意的行为,保护了服务器不被大量的并发请求弄得崩溃,才限制了同一域的最大并发连接数。然而有一些下载软件,它作为一个HTTP协议客户端,不考虑服务器的压力,而发起大量的并发请求(虽然用户感到下载速度很快),但是它违反了规则,所以经常被服务器屏蔽。
为什么服务器对并发请求这么敏感?
因为如果发起多个请求的话,服务器操作系统要为每一个线程创建进程、销毁进程、进程间的切换都是很消耗CPU和内存的,所以当请求数高时,服务器负载高,性能就会下降。
提高服务器的请求处理能力
对于浏览器的请求,后端开发人员要提高服务器的请求处理能力,这里我们介绍几种服务器,介绍各自的特点和性能。
Linux
在早期系统中(比如linux 2.4以前),进程是基本的运作单位,在支持线程系统(Linux 2.6)中,线程才是最基本的运作单位,而进程只是线程的容器。由于线程开销明显小于进程,而且部分资源还可以共享,所以效率比较高。
Apache
Apache是市场份额比较大的服务器,Apache通过模块化的设计来适应各种环境,其中有一个模块叫做多处理模块( MPM ),专门用来处理多请求的情况,Apache安装在不同系统上的时候会调用不同默认 MPM ,在Linux中默认使用的 MPM 是prefork。为了优化,可以改成worker模式。
prefork 与 worker 的区别
prefork的一个进程维持一个连接,而worker的一个线程维持一个连接。所以prefork更加稳定,但是内存消耗更加大,worker没有那么稳定,因为很多连接的线程共享一个进程,当一个线程崩溃的时候,整个进程和所有线程一起死掉。但是worker的内存使用要比prefork 低得多,所以很适合在高HTTP请求的服务器上。
Nginx
在高并发的情况下,Nginx是Apache服务器不错的替代品或者补充:
1、Nginx 更加轻量级,占用更少的资源和内存。
2、Nginx 处理的是异步非阻塞的,而Apache是阻塞的,在高并发下Nginx能保持低资源,低消耗和高性能。
由于Apache和Nginx各有所长,所以经常的搭配是 Nginx 处理前端并发,Apache处理后台请求。
Node.js
V8引擎本身就是用于Chrome浏览器的JS解释部分,但是Ryan Dahl这哥们,鬼才般的,把这个V8搬到了服务器上,用于做服务器的软件。
Node.js是一个专注于实现高性能Web服务器优化的专家,几经探索,几经挫折后,遇到V8而诞生的项目。
Node.js是一个让JavaScript运行在服务器端的开发平台,它让JavaScript的触角伸到了服务器端,可以与PHP、JSP、Python、Ruby平起平坐。
但Node似乎有点不同:
Node.js不是一种独立的语言,与PHP、JSP、Python、Perl、Ruby的“既是语言,也是平台”不同,Node.js的使用JavaScript进行编程,运行在JavaScript引擎上(V8)。
与PHP、JSP等相比(PHP、JSP、.net都需要运行在服务器程序上,Apache、Naginx、Tomcat、IIS。),Node.js跳过了Apache、Naginx、IIS等HTTP服务器,它自己不用建设在任何服务器软件之上。Node.js的许多设计理念与经典架构(LAMP = Linux + Apache + MySQL + PHP)有着很大的不同,可以提供强大的伸缩能力。一会儿我们就将看到,Node.js没有web容器。
Node.js自身哲学,是花最小的硬件成本,追求更高的并发,更高的处理性能。
特点:
所谓的特点,就是Node.js是如何解决服务器高性能瓶颈问题的。
- 单线程
- 非阻塞IO
- 事件驱动
DDos攻击
DDos 是Distributed Denial of Service 的缩写,DDoS攻击翻译成中文就是”分布式拒绝服务”攻击
简单说,就是黑客入侵并控制了大量用户的计算机(俗称”肉鸡”),然后在这些计算机上安装了DDos攻击软件。DDos攻击软件没有想浏览器那样对HTTP并发连接数进行限制,每一个DDos攻击客户端都可以自由设置TCP/IP并发连接数,并且连接上服务器之后,它不会马上断开连接,而是保持这个连接一段时间,知道同时连接的数量大于最大的连接数量,才断开之前的连接。
就这样,攻击者通过海量的请求,让目标服务器瘫痪,无法响应正常的用户请求,以此达到攻击效果。
对于这样的攻击,几乎没有什么特别好的防护方法,除了增加带宽和提高服务器能同时接纳的客户数,另一种方法就是让首页静态化,DDos攻击者喜欢攻击的页面一般是会对数据库进行写操作的页面,这样的页面无法静态化,服务器更容易宕机,DDos攻击者一般不会攻击静态化的页面或者图片,因为静态资源对服务器压力小,而且能够部署在CDN上。
这里介绍的只是最简单个的TCP/IP攻击,而DDos是一个概称,具体来说,有各种攻击方式,比如CC攻击,SYN攻击,NTP攻击,TCP攻击和DNS攻击等。
前端和后端在HTTP上也有交集——BigPie
现有的HTTP数据请求流程是: 客户端建立连接,服务器同意连接,客户端发起请求,服务器返回数据,客户端接收并处理数据。这个处理流程有两个问题。
第一,HTTP协议的底层是TCP/IP,而TCP/IP规定3次握手才建立一次连接。每个新增的请求都要重新建立TCP/IP连接,,从而消耗服务器的资源,并且浪费连接时间。对于几种不同的服务器的资源,并且浪费连接时间。对于几种不同的服务器程序(Apache、Nginx、Node.js等),所消耗的内存和CPU资源也不太一样,但是新的无法避免,没有从本质上解决问题。如下图:
第二问题是,在现有的阻塞模型中,服务器计算生成页面需要时间,等服务器完全生成好整个页面,才开始网络传输,网络传输也需要时间。三者是阻塞式的,每一个环节都在等上一个环节100%完成才开始。页面作为一个整体,需要完整的经历3个阶段才能出现在浏览器中,效率很低。
BigPipe首先把HTML页面分为很多部分,然后在服务器和浏览器之间建立一条管道(BigPipe就是 “大管道” 的意思),HTML的不同部分可以源源不断的从服务器传输到浏览器。BigPie首先输送的内容是框架性HTML结构,这个结构可能会定义每个Pagelet模块的位置和宽高,但是这些pagelet都是空的,就像只有钢筋混凝土骨架的毛坯房。 如下图: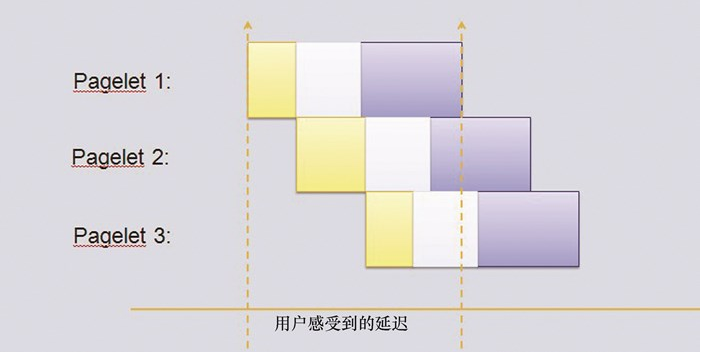
服务器传输完框架性HTML结构之后,对浏览器说:”我这个请求还没有结束,我们保持这个连接不要断开,不过您可以先用我给您的这部分来渲染。”
所以浏览器就开始渲染这个” 不完整的HTML “,毛坯房页面很快出现在用户眼前,具体的页面模块都显示”正在加载”。
接下来管道里源源不断的传输过来很多模块,这个时候最开始加载在服务器中的JS代码开始工作,它会负责把每一个模块依次渲染到页面上。
在用户的感知上,页面非常快地出现在眼前,但是所有模块都显示正在加载中,然后主要的区域(比如重要的用户动态)优先出现,接下来是logo、边栏和各种挂件等。
为什么BigPipe能够让服务器对浏览器说:”我这个请求还没有结束,我们保持这个连接不要断开”呢?答案是 HTTP1.1的分块传输编码。
HTTP1.1引入分块传输编码,允许服务器为动态生成的内容维持HTTP持久链接,如果一个HTTP消息(请求消息或应答消息)的Transfer-Encoding消息头的值为chunked,那么消息体由数量不确定的块组成——也就是想发送多少块就发送多少块——并以最后一个大小为0的块为结束。
实现这个架构需要深刻理解HTTP1.1的规则,而且要有前端的知识。Chrome,Opera,Safari已经支持HTTP/2并默认开启,它允许服务器向浏览器”推送”内容,也就是说,返回的条目数可以比请求的条目数多,这样服务器可以在一开始就推送它认为的浏览器”应该需要”的资源,而不是需要浏览器接受并解析王HTML页面才开始请求下载CSS,JavaScript等,而且,后面的请求可以复用之前已经建立的底层连接。

