不同应用中的B+树索引的使用
在了解了B+树索引的本质和实现了后,那么后面就是要考虑怎么正确的使用B+树索引。但是这个肯定不是一个简单的问题,实际的应用肯定是要考虑多方面的问题。
我们知道数据处理大致分为类:OLTP(传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易)和OLAP(数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果)。在OLTP应用中,查询操只从数据库中取得一小部分数据。一般可能都在10条记录以下,甚至在很多的时候只取一条记录,如:根据主键值来获取用户信息,根据订单号取得订单的详细信息,这都是典型OLTP应用查询语句。在这种情况下,B+数索引才是有意义的,否则即使建立了,优化器也可能不使用索引。
对于OLAP应用,情况可能稍显复杂了,不过概括来说,在OLAP应用中,都需要访问表中大量的数据,根据这些数据来产生查询的结果,这些查询多是面向分析的查询,目的是为决策者提供大量的数据,根据这些数据来产生查询的结果。如果这个月每个用户的消费情况,销售额同比、环比增长的情况。因此在OLAP中索引的添加根据的应该是宏观的信息,而不是微观,因为最终要得到的结果是提供给决策者的。例如,不需要在OLAP中对姓名字段进行索引,因为很少要对单个用户进行查询,但是对于OLAP中的复杂查询,要涉及的多张表之间的连接操作,因此索引的添加依然是有意义的,但是,如果连接操作使用的是Hash Join,那么索引可能又变得不是非常重要的了,所以需要DBA或开发人员认真并仔细的研究自己的应用,不过在OLAP应用中,通常会对时间字段进行索引,这是因为大多数统计需要根据时间维度来进行数据的筛选。
联合索引
联合索引是指对表上的多个列进行索引。联合索引的创建方法与单个索引创建的方法一样,不同之处是有多个索引列。
如下图: 创建一个two_key 表,并且id_fid是联合索引,联合的列是(id, fid)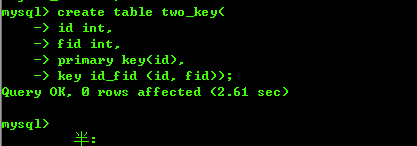
那么联合索引的内部是什么样的呢?
从本质上来说,联合索引也是一颗B+树,不同的是联合索引的键值的数量和不是1,而是大于等于2。接着来讨论两个整数型列组成的联合索引,假设两个键值的名称为id, fid 如图 [多个键值的B+树]: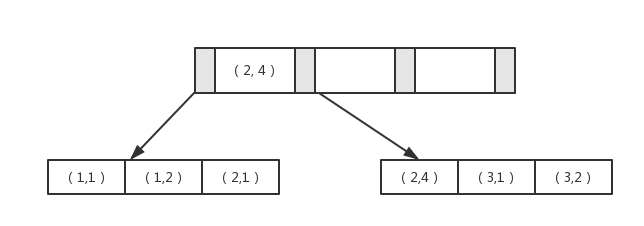
从图中可以看到多个键值的B+树情况,键值都是排序的。通过叶子节点可以逻辑上顺序读取所有数据,就上面图中所示,即为(1,1)、(1、2)、(2、1)、(2、4)、(3、1)、(3、2),数据是按照(id, fid)的顺序进行存放。
所以,对于查询 select * from table two_key where id = XXX and fid = XXX, 像这样的操作显然是可以使用(id, fid)这联合索引的。对于单个列id的查询 select * from two_key where id = XXX 也是可以使用这个联合索引,但是对于fid列的查询 select * from two_key where fid = XXX 则是不能使用这个B+树的联合索引,因为 叶子节点中的fid的值为:1、2、1、4、1、2 显然不是排序的,因此对于fid的查询是使用不到(id, fid )这个联合索引的。
使用联合索引的第二个好处是对已经对第二个键值进行了排序处理。 这里的情况是确定了第一个键,这种情况,对于第一个键相同的记录来说,查询的结果是第二个键是已经进行了排序。我们举一个栗子吧! 例如:有些应用程序都需要查询某个用户的购物情况,并按照时间进行排序,最后取出最近三次的购买记录,这时使用联合索引就可以避免多一次排序操作,因为索引本身在叶子节点已经排序了。
那么来看一个栗子吧:
创建一个buy 表,里面的字段如下,
向表中插入数据,并且修改表,将创建userid索引和(userid, buy_date)联合索引。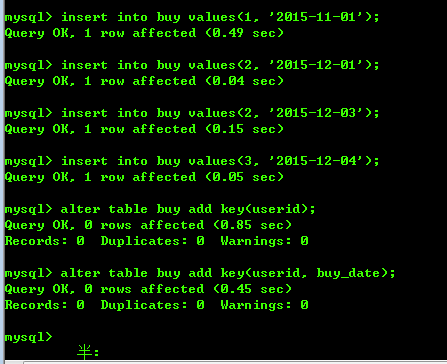
如果执行userid进行查询 select * from buy where userid = 2
在这里使用explain对这条语句进行分析,如图 [ 使用explain分析select查询 ]:
从分析中可以看出在possible_keys中有两个索引可以使用,分别是userid 和 userid_2(即为(userid, buy_date)联合索引),但是优化器最终选择的是userid_2.
但是选择对单列userid进行查询的时候,查询优化器使用的索引是userid,因为查询userid,userid本身就是索引,那么就没有必要使用联合索引了。如下图 [ 单独查询userid使用的索引 ]:
继续看,如果查询userid为2的最近2次的购买记录,那么执行的效果是什么呢? 看下图 [ 查询userid=2最近两次购买请求使用的索引 ]:
对于上述SQL语句既可以使用userid索引,也可以使用联合索引(userid,buy_date),但是优化器使用的是userid_2 ((userid, buy_date)),因为在这个联合索引中buy_date是已经排序好的了,根据这个索引取出的数据,无须再进行第二次的排序操作了。
再来看一个操作,这次是查询所有的信息,并且根据buy_date进行排序,那么我们看是什么执行结果呢?马上放图 [ 不使用联合索引,进行再次排序 ]:
从上图可以知道,在possible_key中并没有可选择的索引,但是优化器最红选择了userid_2 ,因为毕竟有些记录是已经排好序的,但是全部数据并不是有序的,所以从Extra中可以看出多出了一个 Using filesort, 说明使用了第二次排序,即对索引userid_2查询出来的结果进行再次排序。
小小的总结: 联合索引(a, b)其实是根据a、b列进行排序,因此下列语句可以直接使用联索引得到结果:
select * from table where a= XXX order by b然而对于联合索引(a, b,c)来说,下列语句同样可以直接通过联合索引得到结果:
select … from table where a=XXX order by b
select … from table where a=XXX and b =XXX order by c
但是对于下面的语句。联合索引不能直接得到结果,其中还需要执行一次filesort排序操作,因为(a, c)并未排序。
select … from tabel where a=XXX order by c
覆盖索引
InnoDB存储引擎支持覆盖索引(covering index, 或者称索引覆盖) ,即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。使用覆盖索引的一个好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的I/O操作。
对于InnoDB存储引擎的辅助索引而言,由于其中包含了主键信息,因此叶子节点存放的数据为(primary key1, primary key2, …, key1, key2,…)。例如,下面的语句都是可以使用一次联合索引来完成查询:
select key2 from table where key1=xxx;
select primary key2, key2 from table where key1=xxx;
select primary key1, key2 from table where key =xxx;
select primary key1, primary key2, key2 from table where key1 = xxx;
覆盖索引的另一个好处是某些统计问题而言的,还是对于上面建立的buy 表。进行查询 :select count() from buy; 结果如下图 [ 统计查询 ]:
Extra中出现了” select tables optimized away “ 并且前面的一些信息出现的值是 null , 出现这种的情况是: 优化器对于select 语句已经没有再优化的了,根本没有去扫描表就直接得到了。官方的解释是:
For explains on simple count queries (i.e. explain select count() from people) the extra section will read “Select tables optimized away.” This is due to the fact that MySQL can read the result directly from the table internals and therefore does not need to perform the select.
对于(a,b)的联合索引,一般是不可以选择列b中所谓的查询条件。但是如果是统计操作,并且是覆盖索引,则优化器会进行选择。如下操作:select count(*) from buy where buy_date >= ‘2015-01-01’ and buy_date < ‘2017-01-01’ ;
如下图 [ 对于统计的优化查询 ]:
这里只是根据 b 列进行条件查询,一般情况下是不能进行该联合查询的,但是这句SQL查询结果是统计操作,并且可以利用到覆盖索引的信息,因此优化器会选择该联合索引。表中有userid_2索引,possible_keys 中为 null,但是 key 为 userid_2,所以还是使用了覆盖索引。
优化器不使用索引的情况
有些时候,当执行explain命令进行SQL语句的分析时,会发现优化器并没有选择索引去查找数据,而是通过扫描聚集索引,也就是直接进行全表的扫描来得到数据。这种情况多发生于范围查找、JOIN 链接操作等情况。
例如: 在score表中,通过show index from score 可以查看score表中的所有索引,如下图[ score表中的所有索引 ]:
执行select * from score where id > 0 and id <=10;查询分析的结果是什么呢?那么继续看下图:
在possible_keys一列中可以看到查询是可以使用primary key(id) 也可以使用联合索引(id, fid),但是在最后的索引使用中,优化器没有使用任何的索引。
这个是为什么呢?原因在于用户要选取的数据是整行的信息,而id索引不能覆盖到我们要查询的信息,因此在对id 索引查询到指定数据后,还需要一次书签访问来查找整行数据的信息,虽然id索引中数据是顺序存放的,但是再一次进行书签查找的数据是无序的,因此变为了磁盘上的离散读操作。如果要求访问的数据量很小,则优化器还是会选择辅助索引,但是当访问的数占整个表中数据的蛮大一部分的时候,优化器会选择聚集索引来查找数据,因为顺序读取要远远快于离散读取。
索引提示
MySQL数据库支持索引提示(index hint),显示地告诉优化器使用哪个索引。总结有以下两种情况可以使用到index hint:
- MySQL数据库的优化器错误的选择了某个索引,导致SQL语句运行非常慢,这时有经验的DBA或开发人员可以强制优化器使用某一个索引,以此来提高SQL运行的速度。
- 某SQL语句可以选择的索引非常多,这时优化器选择执行计划时间的开销可能会大于SQL语句本身。例如,优化器分析Range查询本身就是比较耗时的操作。这时DBA或开发人员分析最优的索引选择,通过index hint 来强制使优化器不进行各个执行路径的成本分析,直接选择指定的索引来完成查询。
接下来,我们再来看一个例子,创建表 bot,并填充数据。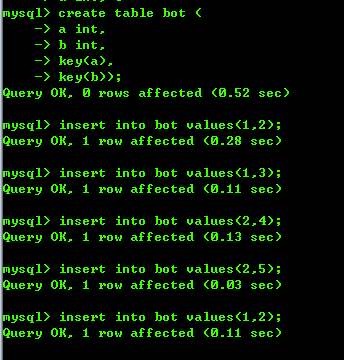
然后执行select * from bot where a = 1 and b = 4;
通过explain 命令可以得到如下图的执行计划:
从图中可以看到,possible_keys中显示了SQL语句可以使用的索引为a,b,而实际使用的索引为列key所示,同样是a,b。也就是MySQL数据库使用两个索引来完成一个查询,列Extra提示Using intersect(b,a)表示根据两个索引得到的结果进行求交数学运算,最后得到结果。
如果我们使用use index 的索引提示来使用 a 这个索引,将会得到如下的结果:
我们可以看到,虽然我们指定使用a索引,但是优化器实际选择的是通过表扫描的方式。因此,use index 只是告诉优化器可以选择该索引,实际上优化器还是会根据自己的判断进行选择。而如果使用force index 的索引提示,又会是什么样的呢? 如下图 [ 强制使用索引 force ]:
可以看到,这时优化器最终选择和用户指定的索引是一致的。因此,如果用户确定指定某一个索引来完成查询,那么最可靠的是使用froce index ,而不是使用 use index.
Multi-Range Read(MRR)优化
MySQL5.6版本开始支持Multi-Range Read(MRR)优化。Multi-Range Read优化的目的就是为了减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问,这对于IO-bound类型的SQL查询语句可能带来性能极大的提升。Multi-Range Read 优化可适用于rang, ref,eq_ref类型的查询。
MRR优化有以下几个好处:
- MRR使得数据库访问变得较为顺序。在查询辅助索引时,首先根据得到的查询结果,按照主键排序的顺序进行书签查找。
- 减少缓冲池中页替被代的次数。
- 批量处理对键值的查询操作。
对于InnoDB和MyISAM存储引擎的范围查询和JOIN查询操作,MRR优化的工作方式是:
- 将查询得到的辅助索引键值存放于一个缓存中,这时缓存中的数据是根据辅助索引键值排序的。
- 将缓存中的键值根据RowID进行排序。
- 根据RowID的排序顺序来访问实际的数据文件。
此外,若InnoDBc存储引擎或者MyISAM存储引擎的缓冲池不是足够大,即不能存放一张表的所有数据,此时频繁的离散读写操作还会导致缓冲池中的页被替换出缓冲池,然后又不断的被读入缓冲池中。如果是按照主键顺序进行访问,则可以将此重复行为降为最低。
是否采用Mutil-Range Read 优化可以通过参数optimizer_switch 中的标记(flag)来控制。当 mrr 为 on 时,表示启用Multi-Rang Read 优化。mrr_cost_based 标记表示是否通过cost based 的方式来选择是否启用mrr。若将mrr设为 on ,mrr_cost_based设置为off,则总是启用Mutil-Range Read优化。例如:
下述语句可以将Multi-Range Read优化总是设为开启状态:
set @optimizer_switch=’mrr=on,mrr_cost_base=off’
例如: 建立下面的表t1,同时创建索引,如图: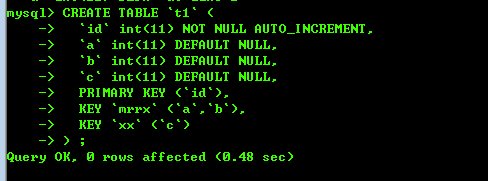
执行查询语句:selcet * from t1 where (a between 1 and 10 ) and (c between 9 and 10);
查询结果如下图[ 使用MRR优化查询结果分析 ]  :
:
从上面,我们可以看到,在使用索引中使用的是 xx 索引,然后 Extra 列中,出现了Using index Condition(ICP优化,后面会讲到) , Using Where, Using MRR。说明查询优化中使用了MRR优化的。
如果没有使用MRR优化查询的话情况是那样的呢!如下图[ 没有使用MRR查询优化 ]:
此外,Multi-Range Read 还可以将某些范围查询,拆分为键值对,以此来进行批量的数据查询。这样做的好处是可以在拆分的过程中,直接过滤一些不符合查询条件的数据。例如:
select * from t where key_part1 >= 1000 and key_part1 < 2000 and key_part2 =1000;
表t中有(key_part1, key_part2)的联合索引,因此索引根据key_part1, key_part2的位置关系进行排序。若没有 Multi-Read Range,此时查询类型为Range, SQL优化器会先将key_part1大于 1000 且小于2000 的数据都取出来,即使key_part2不等于1000.待取出行数据后再根据key_part2 的条件进行过滤,这会导致无用数据被取出。如果有大量的数据且其key_part2不等于1000, 则启用Multi-Range Read优化会使性能有巨大的提升。
如果使用了Multi_Range Read 优化,优化器会先将查询条件进行拆分,然后再进行数据查询。就上述查询语句而言,优化器会先将查询条件进行拆分为(1000, 1000),(1001, 1000),…,(1999,1000),最后再根据这些拆分的条件进行数据查询。
Index Condition Pushdown(ICP)优化
和Multi-Range Read一样,Index Condition Pushdown同样是MySQL 5.6开始支持的一种根据索引进行查询优化的方式,之前的MySQL数据库版本不支持Index Condition Pushdown,当进行索引查询时,首先根据索引来查找记录,然后在根据 where 条件来过滤记录,在支持 Index Condition Pushdown 后,MySQL数据库会在取出索引的同时,判断是否可以进行 where 条件的过滤,也是将where 的部分过滤操作放在了存储引擎层。在某些查询条件下,可以大大减少上层SQL层对记录的索取(fetch),从而提高效率。
Index Condition Pushdown 优化支持rang、ref、eq_ref、ref_or_null 类型的查询,当前支持MyISAM和InnoDB存储引擎,当优化器选择Index Condtion Pushdown优化时,可在执行计划的列Extra看到Using index condition提示。
假设有表为联合索引(zip_code, last_name, first_name), 并且查询语句如下:
select * from people where zipcode = ‘95054’,
and lastname like ‘%ertrunia%’
and address like ‘%Main Street%’;
对于上述语句,MySQL 数据库可以通过索引来定位 zipcode 等于95054的记录,但是索引对于 where 条件的 lastname like ‘%ertrunia%’ and address like ‘%Main Street%’ 没有任何帮助,若不支持 Index Condition Pushdown 优化,则数据库需要先通过索引取出所有 zipcode 等于95054的记录,然后再过滤 where 之后的两个条件。
若支持Index Condition Pushdown优化,则在索引取出时,就会进行where条件的过滤,然后再去获取记录,这将极大地提高查询效率,当然。where可以过滤的条件是要该索引可以覆盖到的范围,有下表,如图 [ 表person ]: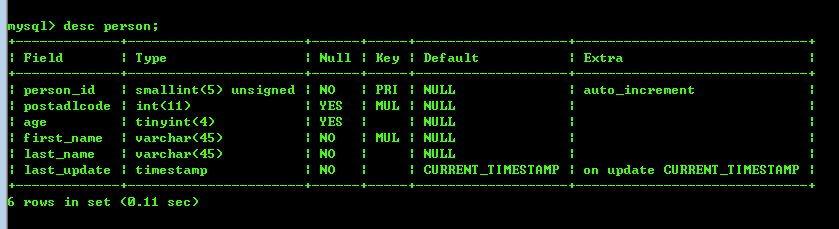
然后进行如下的查询(MySQL 5.7默认是开启Index Condition Pushdown优化的),查询过程如下 [ 使用ICP优化进行查询 ]:
可以看到列Extra有Using index Condition 的提示.如果不使用ICP优化的化,查询过程又是不一样的,首先将ICP优化查询关闭,然后在进行如下的查询,如下图 [ 关闭ICP优化后进行查询 ]: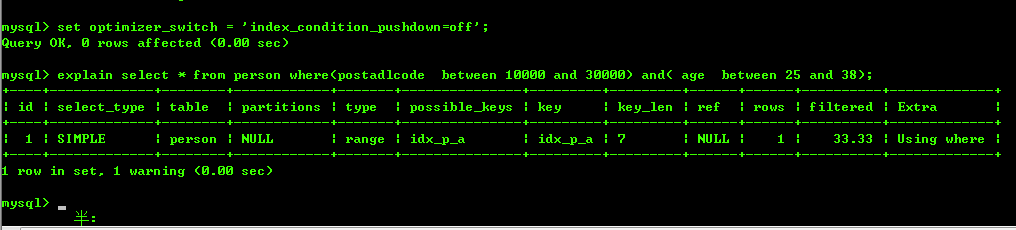
从中可以看到是,在列Extra 中使用的是where,并没有出现了Using index condition .
另外,从收集的资料中对比了MySQL 5.5 和MySQL 5.6 中上述SQL语句的执行时间,并且同时比较开启MRR后的执行时间:
| 执行时间 | |
|---|---|
| MySQL5.5 | 46.738 |
| MySQL5.6 whith ICP | 37.924 |
| MySQL5.6 with ICP&MRR | 7.816 |
上述的执行时间的比较同样是不对缓冲池做任何的预热操作,可见Index Condition Pushdown 优化可以将查询效率在原有MySQL 5.5 版本的技术上提高23%,而再同时启用 Multi-Range Read 优化后,性能还能有400%的提高。

